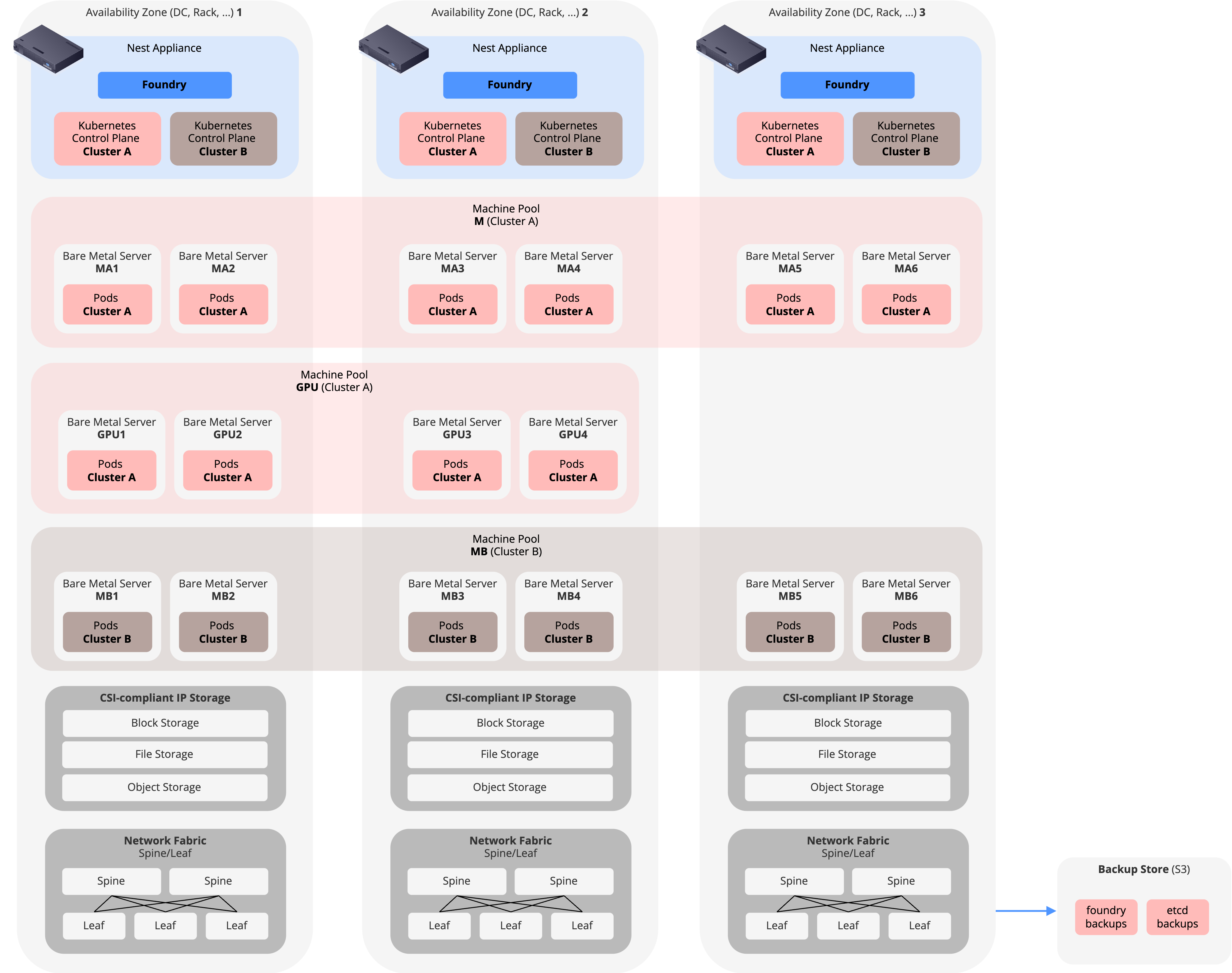
Reference Architecture
The following diagram depicts a production-grade reference architecture, recommended for high available & scale out data center environments:
Remarks:
- Availability Zones: Spread Nest management appliances and worker nodes across different Availability Zones (Failure Domains) for high availability: either accross distinct Racks or distinct data centers.
- Be aware that
etcdrequires an odd number of instances to achieve quorum, so an odd-number of Availability Zones is recommended (for example three racks or data centers).
- Be aware that
- Group servers into Machine Pools and spread them across Availability Zones too; this allows to use them as Update Domains for graceful rollover during updates.
- For CSI-Storage, we recommend using external IP-based storage arrays (significantly simpler and usually better supported by Kubernetes than FibreChannel setups)
- Interconnect the servers, management appliances and storage arrays using a Network Fabric with Spine-Leaf Topology.
- Use a dedicated site as backup location.
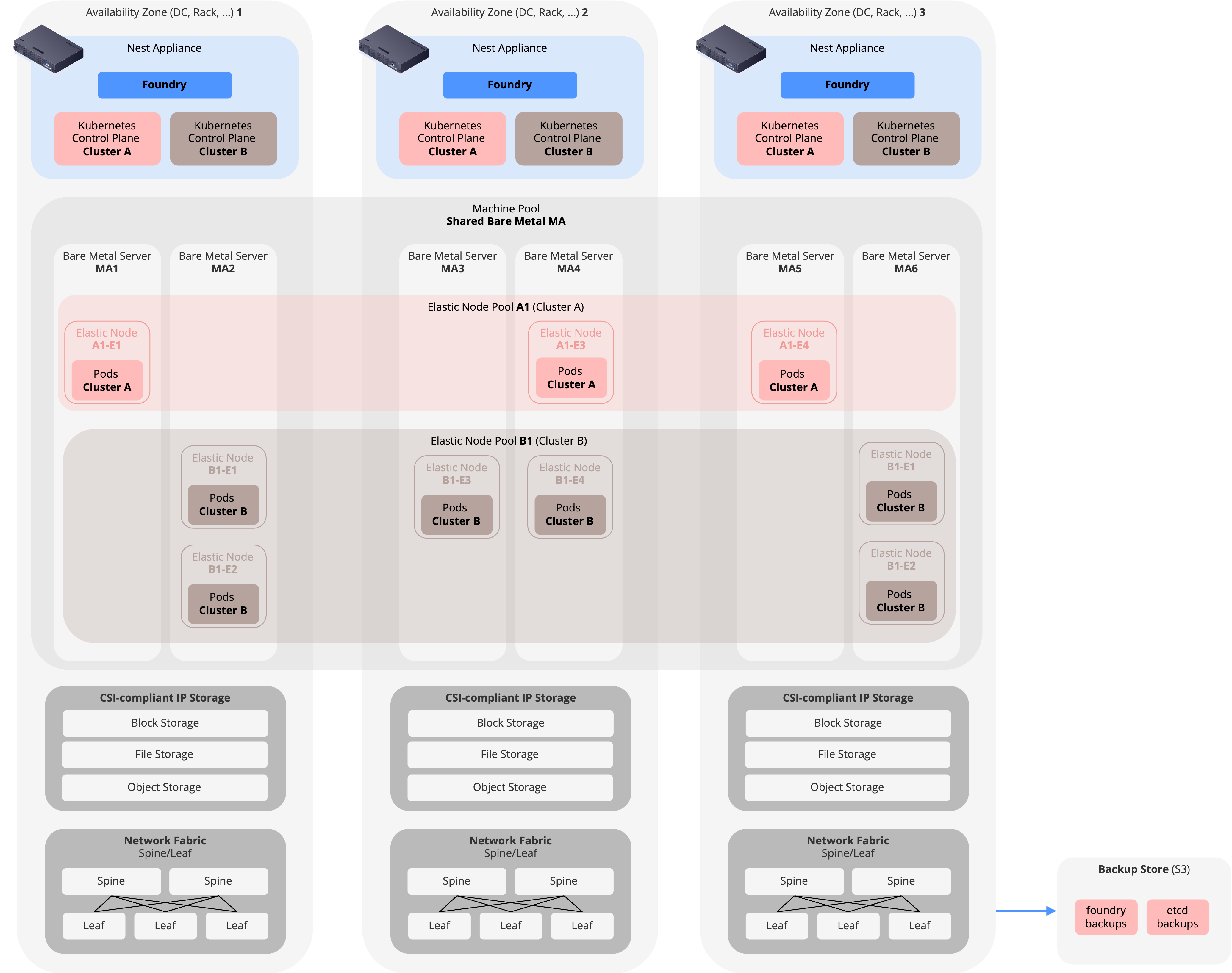
With Elastic Node Pools
The diagram above shows the bare metal foundation using Machines and Machine Pools, where each server is directly assigned to a cluster as a worker node. The following extends this setup with Elastic Node Pools, where the bare metal servers are grouped into a shared Machine Pool and clusters carve virtual workers from it: